Vom Wiegen wird die Sau nicht fett
Warum gutes Monitoring mehr ist als bunte Dashboards
Stefan Hildebrandt
Warum stehe ich hier
- Softwarearchitekt und -entwickler in gewachsenen Systemen
- Brownfield Gardening statt Greenfield-Romantik
- Unterwegs zwischen Entwicklung, Betrieb und Business

Brownfield Gardening in der IT
In gewachsenen Strukturen den Wert des Bestands erkennen
und daraus
etwas Belastbares entwickeln.
Monitoring ist kein Produkt, das man einmal aufsetzt.
- Monitoring ist ein Lern- und Verbesserungsprozess:
- Standards schaffen
- Alerts beherrschbar machen
- Fachmetriken nachziehen
- Lücken systematisch schließen
Frage ans Publikum 1/2
Wer hat Zugriff auf Metriken aus der Produktion
- Technisches Monitoring und Alerting
- Nutzung von Funktionalitäten durch Anwender (aggregiert)
- Business Transaktionen
Frage ans Publikum 2/2
Wer nutzt schon?
- OpenTelemetry (Metrics)
- Prometheus oder Influx
- ELK / Splunk
- Cloud Provider Tools
- APM Suiten
Agenda
- Überblick OpenTelemetry
- Integrationen und Beispiele
- Alerts erstellen und behandeln
- Technische und Fachmetriken verbinden
- Eigene Metriken definieren
Fachliches Beispiel
Ticketshop
- Timeout
OpenTelemetry
otel
OpenTelemetry
- OpenSource Standard für Telemetry
- Basis für Observability Prozesse
- Unterstützung in vielen Plattformen
- Automatische Instrumentierung im Fokus
- Unterschiedliche Backends (OpenSource, SaaS, ...)
- Wird auch von APM-Suiten unterstützt
OpenTelemetry
OpenTelemetry Semantic Conventions
- gemeinsames Vokabular
- Basis für vergleichbares Monitoring über Services hinweg
- Anwendungen unterschiedlich
- Generische alerts mit gleichen Schwellwerten kaum möglich
- Auch über Logs, Traces und Metriken hinweg
OpenTelemetry
Logs
- Historische Vorbilder
- Unix: rsyslogd
- ELK Stack
- Graylog
- Logs können an ein zentrales System übertragen werden
- Einheitliche Schnittstelle
OpenTelemetry - Logs
Beispiel
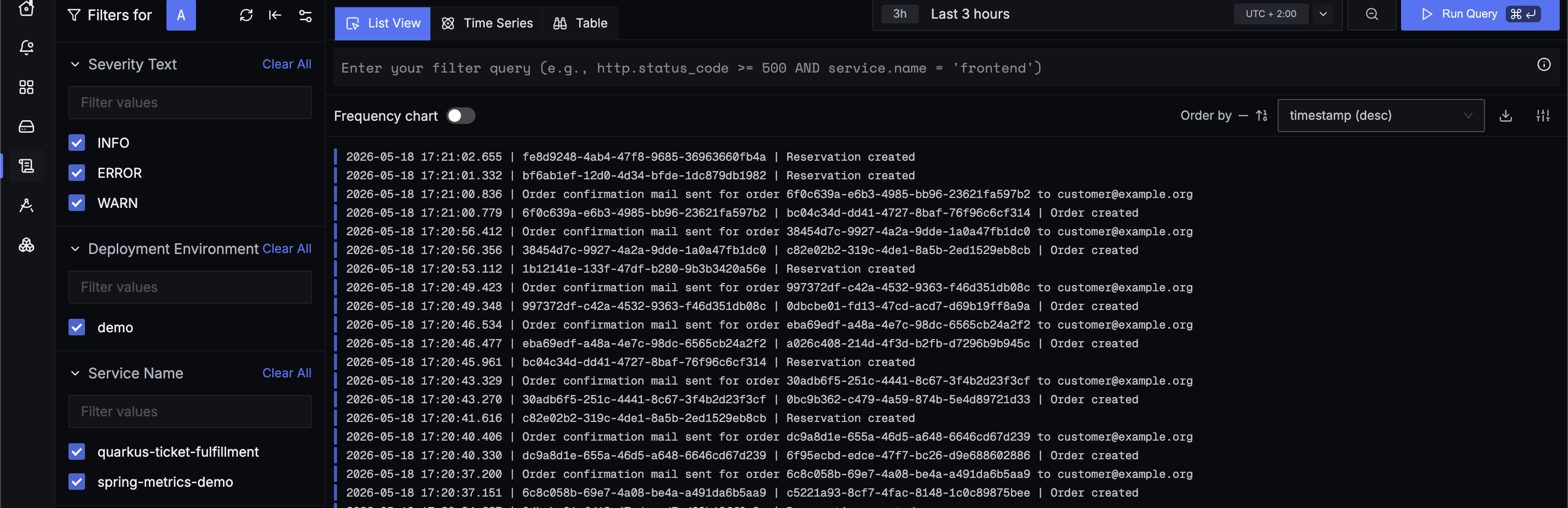
OpenTelemetry
Traces
- Historische Vorbilder
- Jaeger Tracing
- Distributed Tracing - über Systemgrenze
- Microservices
- Start auf Clientseite möglich
- Synchron und Asynchron
- Auch Datenbanken, o.Ä. können eingebunden werden
OpenTelemetry
Traces
- Trace ID als Klammer
- Spans zur weiteren Organisation
- Weiterer Kontext (Parameter, Exceptions, ...)
- Gute Basis fürs Debugging in verteilten Systemen
OpenTelemetry
Metrics
- Historische Vorbilder
- Prometheus
- Einfache Metriken in einer Timelapse DB
- Metadaten einmal gespeichert
- In der Folge Diffs
- Anzahl der Metriken und Änderungen bestimmt Speicherbedarf & Kosten
- Langzeitspeicherung und Reduzierung der Auflösung möglich
OpenTelemetry - Metrics
Standardmetriken
- Schnittstellen: Remote Calls, Messaging, DBs
- Laufzeitumgebung: CPU, Speicher, Festplatte
- Runtime: Garbage Collection, Speichernutzung
OpenTelemetry - Metrics
Struktur
- Name der Metrik
- Attributnamen
- Semantic Conventions für Namen und Attribute
OpenTelemetry - Metrics
Beispiel
- Name: http.server.request.duration.count
- Attribute:
- service.name
- http.route
- http.request.method
- url.scheme
- http.response.status_code
- error
- outcome
- ...
OpenTelemetry - Metrics
Beispiel
- Name: http.server.request.duration.sum
- Attribute:
- service.name
- http.route
- http.request.method
- url.scheme
- http.response.status_code
- error
- outcome
- ...
OpenTelemetry - Metrics
Beispiel
- Name: http.server.request.duration.sum
- Name: http.server.request.duration.count
- rate(count) -> Requests per Second
- rate(count{error!="none"}) -> Errors per Second
- sum / count -> Durchschnittliche Antwortzeit
OpenTelemetry - Metrics
Beispiel
Weitere Integrationen
Integration
Integration
Java Default
- Agent
- + Environment Variablen
- Byte Code Instrumentalisierung
- Integrationen
- HTTP Server und Client
- Kafka
- JVM
- ...
- Mögliche Versionskonflikte
Integration
Spring Boot 4 (Spring Way)
- spring-boot-starter-opentelemetry
- + Programmatische Konfiguration
- + Environment Variablen
- Kein Agent
Integration
Quarkus
- quarkus-opentelemetry
- quarkus-micrometer-opentelemetry
- + Environment Variablen
- Kein Agent
Integration
Quarkus
quarkus.otel.exporter.otlp.endpoint=http://localhost:4317
quarkus.otel.traces.sampler=parentbased_always_on
quarkus.otel.logs.enabled=true
quarkus.otel.metrics.enabled=true
Definition von Alerts
Definition von Alerts
Natürliche Trigger
- Service Einschränkung für Clients
- Downstream Systeme unzuverlässig
- Kritische Systemzustände und Resourcenknappheit
- Bevor Einschränkungen für Nutzer auftreten
- Unerwartet niedrige Geschäftszahlen
Definition von Alerts
Beispiel
Umgang mit Alerts
Umgang mit Alerts
Verbindlichkeit
- Keine "dauerroten" und flaky Alerts tolerieren
- Gar keine Alerts ignorieren
Umgang mit Alerts
ALARM, ALARM
- Entsprechend der Prio bearbeiten
- Mehrere Klassen: Critical, Major, Minor
- Ticket anlegen
- Dokumentieren
- Aktion
- Vertrauen in Alerts schützen
Umgang mit Alerts - Aktion
OODA-Schleife
- Observe
- Was ist wann passiert?
- Orient
- Abgleich: Daten und Lösungen?
- Decide
- Klar, Unklar?
- Act
- Restart, Rollback, Eskalation, Runbook Update, ...
Umgang mit Alerts - Aktion
Bekannter Fehler
- Runbook befolgen
- In Log-Buch aufnehmen, um Häufung zu erkennen
- Regelmäßiges Feedback für Entwicklungsteams
- Gemeinsames Backlog mit Monitoring Tasks
Umgang mit Alerts - Aktion
Runbooks
- Eindeutig
- Auch nachts um 3h
- Kleinteilig
- Ohne Interpretationsspielraum
- Links, Accounts, Knöpfe, Commandos, ...
- Klare Eskalationsmarker
- Verprobt
Umgang mit Alerts - Aktion
Runbooks - Beispiel
- Alert Kafka Consumer hängt
- Prüfe auf dem Board
- Prüfe ob Emails versendet werden können Mail Board
- Falls Probleme mit dem Emailversand bestehen, den Mailserver prüfen Board und dann dem Runbook für den Email-Server folgen
- ...
Umgang mit Alerts - Aktion
Monitoring Backlog - Beispiel
- Flaky Alert für Fehler bei wenig Trafik auf Order Endpunkt fixen
- Alert für unerkanntes Problem TS-13213 vom 17.5.2026 erstellen
- MDC Logging in Quarkus an Spring anpassen
- Stabile Basismetrik für Kafka Consumer Lag in Board und Alert verwenden
- Runbook für Kafka Lag Alert erweitern
Umgang mit Alerts - Aktion
Ursache Beheben
- Root Cause Analyse
- Intern / externer Trigger
- Performance Probleme
- Wackler in der Infrastruktur
- Skalierung
Umgang mit Alerts - Aktion
Alert anpassen
- Schwellwerte
- Betrachtungszeiträume
- Fehler außerhalb des eigenen Einflusses ausklammern
- 400, 401, 404
- Absolute Werte bei Low Traffic Endpoints. statt
- Fehlerquote > 10%
- Kein erfolgreicher Request über Zeitraum X
Umgang mit Alerts - Aktion
Silence
- Bis Workaround & Behebung des Problems umgesetzt und deployed sind
- Falls notwenig während Deployments & Backups (z.B. Load)
- Bis Ticket bearbeitet wird
Fehler, aber kein Alert
- Ticket anlegen
- Ursache Analysieren
- Alert definieren
- In Daten erkennbar?
- Zusätzliche Metriken notwendig?
Technisch gesund heißt nicht fachlich gesund
Fachliche Sicht
Fachliche Sicht
Bestellungen
Fachliche Sicht
Umsatz
Fachliche Sicht
Conversion Rate
Fachliche Sicht
Abbruch bei Zahlungsdienstleistern
Fachliche Sicht
Auftrennung nach Kanal (Web, Mobil, ...)
Fachliche Sicht
Einstiegspunkte
- Werbung
- Suchmaschinen
- KI Agenten
Fachliche Sicht
Feature Nutzung in Anwendungen
- A-B Tests
- MVP Verprobung
Fachliche Sicht
Bearbeitete Geschäftsvorfälle
- Ggf. rechtlich kritisch
Beispiel im Ticket-Shop
- Timeout der Reservierung nach 15s
Grenzen von technischen Metriken
Limitierung von technischen Metriken
Typische technische Metriken
- http-Requests je URI und http-Methode
- Kafka-Nachrichten
Limitierung von technischen Metriken
Detailgrad: http-Requests
- Bei CRUD relativ gute Differenzierung
- GraphQL limitierter
- Bei Events over HTTP (Webhocks)
- Unterschiede möglicherweise in der Nachricht
Limitierung von technischen Metriken
Detailgrad: Messages
- Nur 1 Nachrichtentyp je Topic kann funktionieren
- Ansonsten analog zu HTTP Events
Limitierung von technischen Metriken
Fachlich nicht sprechende Namen!
Die Bruecke zu Fachmetriken
Gleicher Stack, andere Sprache
Beispiel
Übersichten und Alarme mit fachlichem Impact
Implementierung
- Zählertypen
- sums, gauges, summaries, histograms, and exponential histograms
- Intention
- Funktionsweise
Deep Dive
Implementierung Custom Metrik
Limitierungen
Limitierungen
Metrikerstellung
- Nach Start angelegte Counter starten nicht bei 0
- Eigene Zähler je Knoten
Limitierungen
Kardinalität
- Je eine Metrik für die Kombination aus Name und Attributwerten
- Ein Eintrag je geändertem Wert
- Kosten Abhängig von Attributanzahl und Frequenz
- Speicherung
- Abfragen (Cloud!)
Limitierungen
Langzeitarchivierung
- Mittelwerte werden gespeichert
- Min und Max Werte gehen verloren
- Ungeeignet für hart abgrenzendes Reporting
Ausblick: Im Frontend
- Eigener Endpoint für fachliche Events im Frontend
- Einschränkung auf limitierten Wertebereich
- Keine zweite Datenplattform nötig
Ausblick: Im Frontend
- Eigener Endpoint für fachliche Events
- Keine zweite Datenplattform nötig
- Schneller als nachgelagerte Batch-Pipelines
- Dashboards und Alerts bleiben im selben System
Take-away
- Mit OpenTelemetry-Standards anfangen
- Business-Impact sichtbar zu machen
- Alerts über OODA, Runbooks und Pflege belastbar machen
- Aus jedem Incident das Monitoring gezielt verbessern
Fragen?
Slides
